
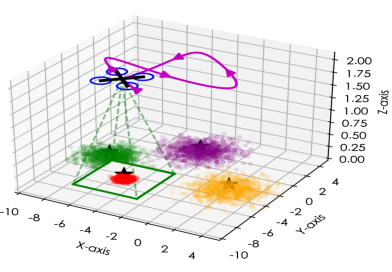
【图/文 华政宇】无人机(Unmanned Aerial Vehicle, UAV)在有限视野下的多目标搜索与跟踪(Search and Tracking, SaT)面临着巨大的挑战,系统必须在保持对视野内可见目标的精确位置估计,与重新寻回因间歇性观测而丢失的目标之间取得平衡。传统的随机有限集(Random Finite Set, RFS)或网格化方法在目标脱离视野时往往难以维持显式的搜索表示,导致无人机容易陷入“探索-开发”困境。为了应对这一问题,我们提出了一种整合的主动感知框架——基于注意力机制和混合置信度强化学习(Hybrid Belief Estimation Reinforcement Learning, HyBE-RL)的规划方法。该方法在估计层引入了一种依赖于可见性的耦合机制,利用未检测到的“负信息”在观测间隙维持高保真的先验分布。在规划层,HyBE-RL利用空间-不确定性注意力机制,直接将连续的置信度状态映射为最优控制动作,从而克服了传统几何规划器固有的离散化伪影和启发式次优性。为了实现稳健的强化学习训练和安全的现实部署,该框架还结合了一个基于采样的几何规划器以提供专家级的奖励引导和运行时的安全护盾。在数值仿真与Gazebo逼真物理仿真中,针对多达7个动态目标的追踪测试表明,该方法在信息增益和跟踪误差方面均表现优异。在真实世界的无人机实验中,HyBE-RL被部署于追踪多个目标,在存在物理遮挡、目标突然位移等复杂场景下,依然实现了卓越的伺服成功率、重新寻回丢失目标的能力和极低的平均绝对误差(Mean Absolute Error, MAE),全面超越了传统的基于卡尔曼滤波的强化学习(Kalman Filter Reinforcement Learning, KF-RL)基线及几何教师算法。
主要贡献:
- 提出了统一的混合置信度估计器(Hybrid Belief Estimation, HyBE):该估计器能够在间歇性观测下严格量化多目标的不确定性动态。通过动态耦合参数化跟踪层(针对检测目标的高效卡尔曼滤波)与非参数化搜索层(针对未检测目标的粒子分布),HyBE显式地利用未检测带来的“负信息”重塑概率分布,为平衡精确跟踪与重新寻回目标提供了鲁棒的概率基础。
- 设计了注意力驱动的强化学习规划器(HyBE-RL): 该规划器旨在掌控高维置信度空间中主动信息获取的复杂性。通过利用空间-不确定性注意力机制,HyBE-RL有效地提取了无人机与多个目标置信度之间的关系特征,将连续状态直接映射为“非近视”(non-myopic)的长期最优控制动作,彻底摆脱了传统网格表征的分辨率限制。
- 引入了专家引导训练与在线安全切换策略: 为解决纯强化学习在复杂环境下的安全与收敛难题,我们集成了一个几何规划器(HyBE-Dijkstra)。该几何规划器在训练初期提供专家动作演示以实现高效的奖励塑造,并在实际部署时作为在线的“白盒”安全护盾,确保无人机在杂乱和有障碍物环境中的绝对运动安全。消融实验与真实飞行测试均证实,该设计在不牺牲跟踪性能的前提下显著提升了系统生存率与可靠性。
论文引用:
Zhengyu Hua, Yike Wu, Yuwei Li, Li Xing, Jidong Huang, Peng Li, Wencan Lu*, and Haoyao Chen*. Informative Planning with Attention-based Hybrid Belief Reinforcement Learning for Aerial Multi-Target Search and Tracking, in IEEE Robotics and Automation Letters, 2026, doi: 10.1109/LRA.2026.3700661.